Prototypage et évaluation comparative de la prédistorsion numérique basée sur l’apprentissage automatique avec le matériel RF de NI
Aperçu
La prédistorsion numérique (DPD) des amplificateurs de puissance (PA) reste un domaine de recherche actif, et l’apprentissage automatique offre des perspectives intéressantes pour relever les défis des systèmes de communication modernes. Dans cet article, nous avons montré comment nous avons utilisé la plateforme RF de NI pour implémenter une application prototype destinée à entraîner un modèle de DPD basé sur le machine learning (ML-DPD), à partir de données waveform issues d’un PA réel. Nous avons validé les performances de prédistorsion du ML-DPD avec ce PA et comparé ses résultats à ceux d’autres algorithmes de pointe. Nous partageons les principaux enseignements tirés de cette expérimentation, et faisons le point sur les défis et les pistes de recherche liés à l’utilisation de la DPD basée sur le ML dans des environnements de déploiement concrets.
Contenu
- IA/Apprentissage automatique dans les communications RF et sans fil
- Présentation de la prédistorsion numérique
- Prédistorsion numérique basée sur l’apprentissage automatique
- Application de prototypage et d’évaluation du ML-DPD
- Résultats d’exemple
- Résumé et conclusion
- Références
- Étapes suivantes
IA/Apprentissage automatique dans les communications RF et sans fil
Les avancées spectaculaires de l’intelligence artificielle (IA) et de l’apprentissage automatique (ML) ces dernières années ouvrent de nouvelles perspectives pour relever des défis complexes dans de nombreux secteurs. Dans le domaine des communications sans fil, l’intégration de l’IA/ML s’impose comme l’une des technologies les plus prometteuses pour proposer de nouveaux services et améliorer les réseaux mobiles.1 Parmi ses atouts, l’IA/ML permet notamment aux opérateurs de réseaux mobiles (MNO) d’optimiser l’efficacité de leurs infrastructures et de réduire leurs coûts d’exploitation, un objectif stratégique pour ces acteurs. Ces avancées pourraient se traduire par une utilisation plus efficiente du spectre, grâce à une allocation plus intelligente des ressources dans les domaines temporel, fréquentiel et spatial, ou encore à de meilleurs mécanismes de compensation des interférences. De plus, l’IA/ML pourrait également permettre des gains en efficacité énergétique, afin de répondre à l’un des principaux postes de dépenses des stations de base. Par exemple, une gestion plus intelligente de l’activation et de la mise en veille des stations, en fonction des besoins, permettrait d’optimiser l’utilisation des amplificateurs de puissance.
Si l’IA/ML est déjà utilisée avec succès à l’échelle du réseau, son application aux couches inférieures (comme la couche RF, la couche physique (PHY) ou la couche MAC) soulève encore de nombreux défis. Les contraintes temporelles très strictes à ces niveaux rendent le développement et le déploiement d’algorithmes IA/ML robustes et fiables plus complexes, en particulier lorsqu’il s’agit de surpasser les méthodes traditionnelles.2 Ce domaine reste donc en phase de recherche active, afin de mieux cerner les arbitrages nécessaires à une mise en œuvre pertinente de l’IA/ML, et de démontrer la robustesse et la fiabilité de ces algorithmes dans des conditions réelles de déploiement réseau. En définitive, il est indispensable de démontrer que l’usage de l’IA/ML offre des avantages tangibles par rapport aux approches traditionnelles afin de justifier de nouveaux investissements.
Les recherches actuelles sur l’intégration de l’IA/ML dans les couches RF, PHY et MAC des systèmes de communication sans fil se concentrent notamment sur les domaines suivants :
- RF : la prédistorsion numérique (DPD) basée sur le ML, visant à améliorer le rendement des amplificateurs de puissance et à réduire la consommation d’énergie ;
- PHY : l’estimation de canal et la détection de symboles à l’aide d’algorithmes ML, afin d’optimiser l’efficacité spectrale en utilisant moins (voire pas) de symboles pilotes, et d’améliorer l’efficacité énergétique en conservant une qualité de transmission équivalente avec un rapport signal/bruit réduit ;
- MAC : la gestion des faisceaux (beam management) via le ML, pour faciliter l’acquisition et le suivi des faisceaux, avec pour objectif d’orienter le rayonnement d’un réseau d’antennes vers un utilisateur donné. Avec cela, le spectre peut être utilisé plus efficacement en desservant davantage d’utilisateurs dans une cellule. De plus, l’énergie peut être économisée en adaptant le rapport signal sur bruit au récepteur aux besoins réels de qualité de service.
Dans un autre livre blanc publié par NI, nous avons présenté un cadre de prototypage et d’évaluation d’un récepteur neuronal en temps réel, en utilisant les dispositifs SDR de NI. Dans ce livre blanc, nous présentons une étude de cas illustrant comment prototyper et évaluer des algorithmes d’apprentissage automatique pour la prédistorsion numérique (DPD) d’amplificateurs de puissance, à l’aide du matériel RF de NI. Nous proposons un bref aperçu de quelques types de réseaux neuronaux couramment étudiés pour la DPD. Nous expliquons également comment nous avons mis en œuvre une application de prototypage permettant d’entraîner un modèle de DPD basé sur le ML à partir de waveforms issues d’un amplificateur de puissance réel, de valider ses performances en matière de prédistorsion avec ce même amplificateur, puis de comparer ses résultats à ceux d’autres algorithmes de pointe. Enfin, nous partageons les principaux enseignements tirés de cette expérimentation, et faisons le point sur les défis et les pistes de recherche liés à l’utilisation de la DPD basée sur le ML dans des environnements de déploiement concrets.
Présentation de la prédistorsion numérique
Il est bien établi que les amplificateurs de puissance (PA) offrent leur meilleur rendement lorsqu’ils fonctionnent en régime non linéaire. Malheureusement, dans cette zone de fonctionnement, les PA génèrent des émissions hors bande indésirables dues aux intermodulations, elles-mêmes causées par les caractéristiques non linéaires de l’amplificateur. La prédistorsion numérique (DPD) est généralement appliquée à la waveform de l’émetteur pour compenser ces distorsions. La compensation (ou prédistorsion) consiste à appliquer, en bande de base numérique, l’inverse de la non-linéarité du PA, de manière à ce que la réponse combinée du système DPD et du PA redevienne linéaire. La figure 1 illustre ce principe de compensation. Ainsi, la DPD permet à un amplificateur de fonctionner dans une zone non linéaire avec un rendement énergétique plus élevé, tout en maintenant la linéarité du signal.
L’augmentation constante des débits de données nécessite des bandes passantes plus larges, souvent disponibles uniquement à des fréquences porteuses plus élevées, lesquelles impliquent l’utilisation de réseaux d’antennes pour focaliser l’énergie et compenser les pertes de propagation importantes. Pour les amplificateurs de puissance (PA) spécifiquement conçus pour fonctionner dans ces conditions, la mise en œuvre de la DPD devient de plus en plus complexe, et ce pour plusieurs raisons :
- Le comportement non statique des PA, dont le modèle sous-jacent évolue en fonction des conditions dynamiques de fonctionnement ;
- La complexité croissante des non-linéarités des PA, rendant les modèles classiques basés sur les séries de Volterra inadaptés.
Face à ces défis propres aux systèmes de communication modernes, il devient nécessaire d’explorer des approches innovantes pour la DPD. L’apprentissage automatique représente l’une de ces approches prometteuses, actuellement au cœur des travaux de recherche menés par le monde académique et l’industrie. Nous décrirons cette approche dans la section suivante.
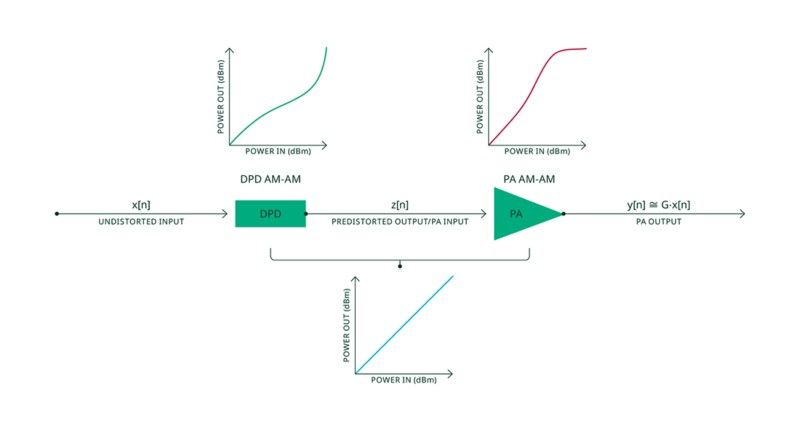
Figure 1. Principe de la prédistorsion numérique
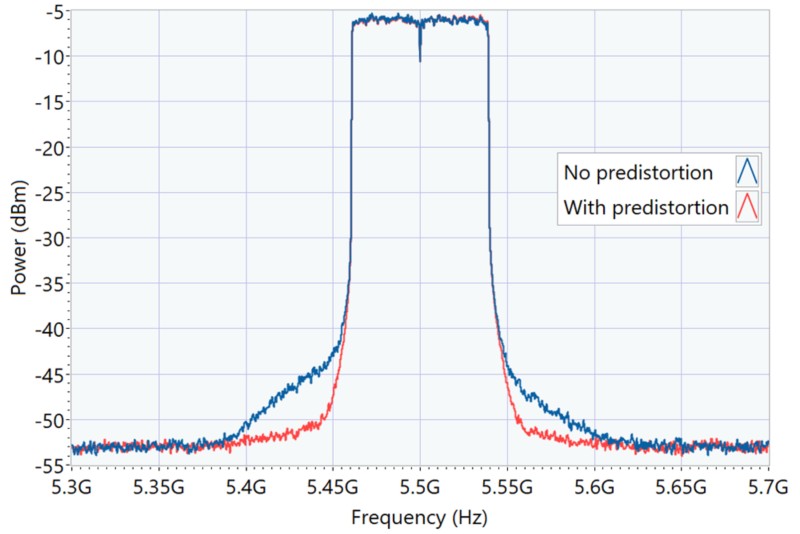
Figure 2. Réduction des fuites spectrales grâce à la DPD
La figure 2 illustre un exemple d’atténuation des fuites spectrales permise par la prédistorsion numérique, en comparant le signal de sortie d’un PA Wi-Fi avec et sans application de DPD. Le principal défi de la DPD consiste à estimer la non-linéarité de l’amplificateur de puissance utilisé, autrement dit à modéliser avec précision le comportement du PA. Traditionnellement, pour des non-linéarités sans mémoire, on utilise des tables de correspondance statiques (lookup tables) basées sur les distorsions mesurées AM/AM et AM/PM. Pour traiter les non-linéarités avec mémoire, on a généralement recours à des modèles fondés sur les séries de Volterra, comme le modèle polynomial à mémoire (MPM) ou le modèle polynomial généralisé à mémoire (GMP).
Prédistorsion numérique basée sur l’apprentissage automatique
Les réseaux neuronaux font l’objet de nombreuses recherches dans le domaine de la modélisation comportementale et de la prédistorsion numérique, en raison de leur capacité à représenter des systèmes non linéaires (à l’image d’un amplificateur de puissance présentant un comportement non linéaire avec effets de mémoire non linéaire).
Il y a une vingtaine d’années, une équipe a proposé5 un modèle neuronal temporel à retard réel (RVTDNN), fondé sur une structure de perceptron multicouche (MLP), pour modéliser le comportement des amplificateurs 3G. Le modèle utilisait des lignes à retard appliquées aux composantes en phase (I) et en quadrature (Q) du signal, afin de capturer les effets de mémoire à court terme du PA. Un réseau de neurones entièrement récurrent (FRNN) a été proposé pour la modélisation comportementale des amplificateurs de puissance dans les systèmes de communication cellulaire 3G, caractérisés par de forts effets de mémoire combinés à une forte non-linéarité. Ce modèle utilise des signaux complexes en entrée, avec des poids et des biais également complexes. La prédistorsion numérique d’amplificateurs de puissance à l’aide de réseaux neuronaux a fait l’objet d’études approfondies et a été validée dans le cadre de signaux WCDMA.7 À cette occasion, un réseau neuronal temporel à retard focalisé en valeurs réelles (RVFTDNN) a été proposé, afin d’éviter les calculs de gradients complexes.
Les réseaux de neurones récurrents (RNN) possèdent intrinsèquement la capacité de modéliser des effets de mémoire, c’est-à-dire des situations où la sortie actuelle dépend non seulement de l’entrée courante, mais aussi des entrées passées. Cependant, les RNN rencontrent des difficultés à capturer les effets de mémoire à long terme en raison du problème bien connu de l’extinction des gradients (vanishing gradients). Pour remédier à cela, les réseaux à mémoire à long terme (LSTM) ont été introduits.8
Les réseaux LSTM utilisent différents types de portes (gates) permettant de mieux contrôler dans quelle mesure les informations passées et nouvelles influencent les états de mémoire du réseau.9 Dans le cadre de la modélisation comportementale d’amplificateurs GaN présentant des effets de mémoire à long terme, une équipe a étudié l’utilisation de réseaux LSTM comme alternative aux limitations des FRNN.7 D’autres variantes optimisées des réseaux basés sur les RNN, telles que les réseaux LSTM bidirectionnels (BiLSTM) et les unités récurrentes avec portes (GRU), sont également décrites dans la littérature pour des applications de prédistorsion numérique.11,12 Récemment, les réseaux de neurones convolutifs (CNN) ont également été explorés pour la modélisation comportementale et la prédistorsion des amplificateurs de puissance.13
Des réseaux neuronaux ont aussi été proposés pour éviter la mise à jour continue des paramètres de prédistorsion numérique dans les systèmes MIMO massifs dotés de réseaux d’antennes actives, qui présentent des effets de modulation de charge dépendants du faisceau.14 Dans le cadre de cette étude de cas, nous avons choisi de mettre en œuvre un réseau neuronal de type LSTM pour la DPD.
La figure 3 présente les différentes couches de notre réseau implémenté. Ce réseau reçoit en entrée des échantillons du signal complexe en domaine temporel non distordu x[n], et génère en sortie des échantillons du signal complexe prédistordu z[n]. À chaque instant temporel, les entrées de la couche LSTM sont les composantes en phase (I) et en quadrature (Q) du signal actuel et des M échantillons précédents, où M représente la profondeur mémoire.
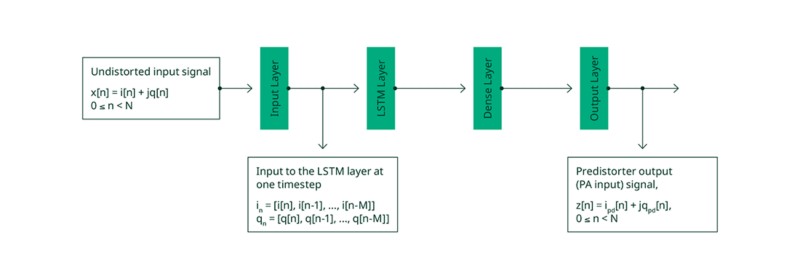
Figure 3. Architecture du modèle
Le réseau neuronal doit apprendre la fonction cible de prédistorsion numérique (DPD) à partir d’un ensemble de données d’apprentissage, lors de la phase d’entraînement. Parmi les architectures d’apprentissage couramment utilisées pour un modèle DPD, on peut citer l’architecture d’apprentissage direct (DLA), l’architecture d’apprentissage indirect (ILA), ou encore l’architecture basée sur le contrôle par apprentissage itératif (ILC). Pour notre étude de cas, nous avons retenu l’approche ILC comme source des données d’apprentissage, car elle permet de générer un signal d’entrée prédistordu optimal, capable de linéariser efficacement le PA.
La DPD basée sur l’ILC constitue une référence précieuse pour évaluer les performances de toute autre approche de prédistorsion.
La figure 4 illustre l’architecture d’apprentissage de l’ILC, qui permet de calculer de manière itérative un signal de sortie du prédistordeur z[n], également utilisé comme signal d’entrée de l’amplificateur, à partir d’un signal d’entrée non distordu x[n]. Après un nombre suffisant d’itérations, le signal z[n] obtenu peut être considéré comme le signal de prédistorsion idéal, noté z_ideal [n] et comme l’entrée idéale pour le PA.
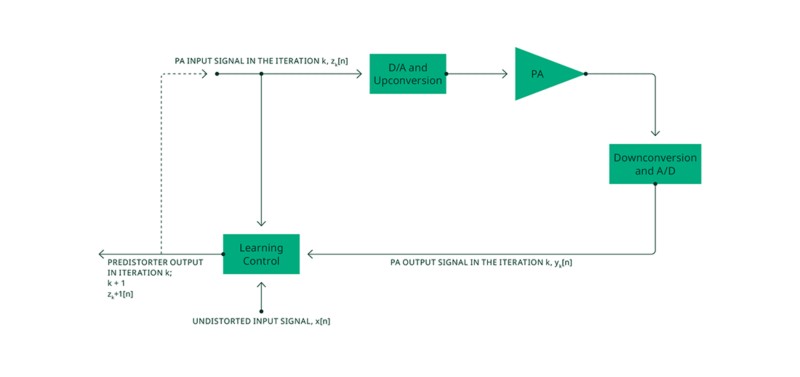
Figure 4. Architecture d'apprentissage : contrôle par apprentissage itératif
Une ou plusieurs paires composées d’un signal d’entrée non distordu et du signal de prédistorsion idéal correspondant peuvent être utilisées pour entraîner ou ajuster les paramètres de tout modèle DPD, qu’il s’agisse d’un modèle polynomial généralisé à mémoire traditionnel ou, comme dans notre cas, d’un réseau neuronal. Durant l’apprentissage, le ou les signaux de sortie idéaux servent de référence (ground truth) que le modèle DPD doit apprendre à reproduire en sortie, à partir des signaux d’entrée correspondants. Ce processus est représenté à la figure 5.
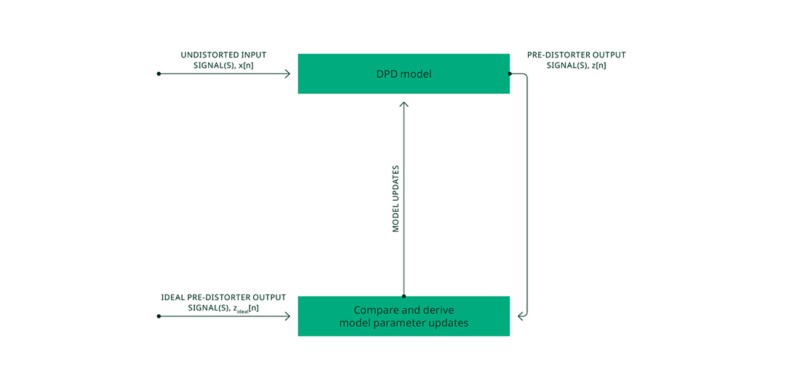
Figure 5. Formation au modèle DPD
Application de prototypage et d’évaluation du ML-DPD
Nous avons développé une application prototype pour étudier l’ensemble du flux de travail d’une implémentation de DPD basée sur l’apprentissage automatique.
L’application s’exécute sur un contrôleur PXI installé dans un châssis PXI NI, en utilisant un transcepteur de signaux vectoriels PXI NI (VST) pour générer et analyser les signaux RF, ainsi qu’une unité de source et mesure PXI NI pour fournir la puissance DC et piloter les lignes de commande numériques de l’amplificateur de puissance. Un diagramme de la configuration test utilisée est présenté à la figure 6.
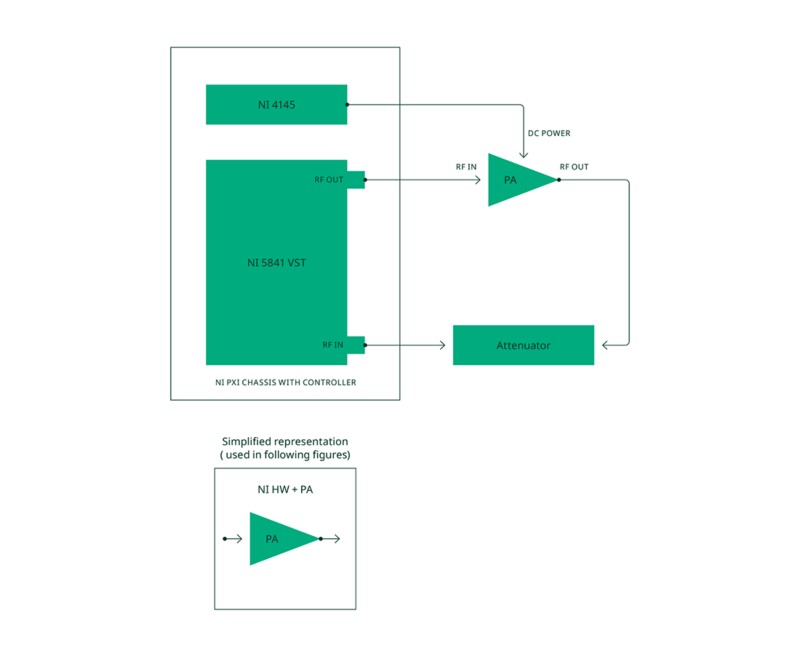
Figure 6. Configuration test montrant les connexions matérielles
L’application permet d’exécuter les étapes suivantes :
- Générer des données waveform pour l’entraînement et les tests ;
- Créer un jeu de données d’entraînement à partir d’un amplificateur de puissance réel ;
- Utiliser ce jeu de données pour entraîner un modèle de réseau neuronal ;
- Déployer le modèle entraîné afin de prédistordre le signal d’entrée envoyé à un PA réel.
Ces actions utilisateur sont illustrées à la figure 7. Les sections suivantes les détailleront. À l’exception de l’entraînement du modèle neuronal, l’application a été développée dans NI LabVIEW. Elle utilise le logiciel RFmx NI pour réaliser des mesures RF standards sur l’amplificateur de puissance à l’aide d’un transcepteur de signaux vectoriels (VST) NI. Elle s’appuie également sur NI RFmx Waveform Creator pour générer les fichiers waveform. L’entraînement du modèle de réseau neuronal est quant à lui réalisé en Python, à l’aide des bibliothèques TensorFlow et Keras. Pour accélérer le traitement, cette phase est exécutée sur un serveur Linux équipé d’un GPU NVIDIA.
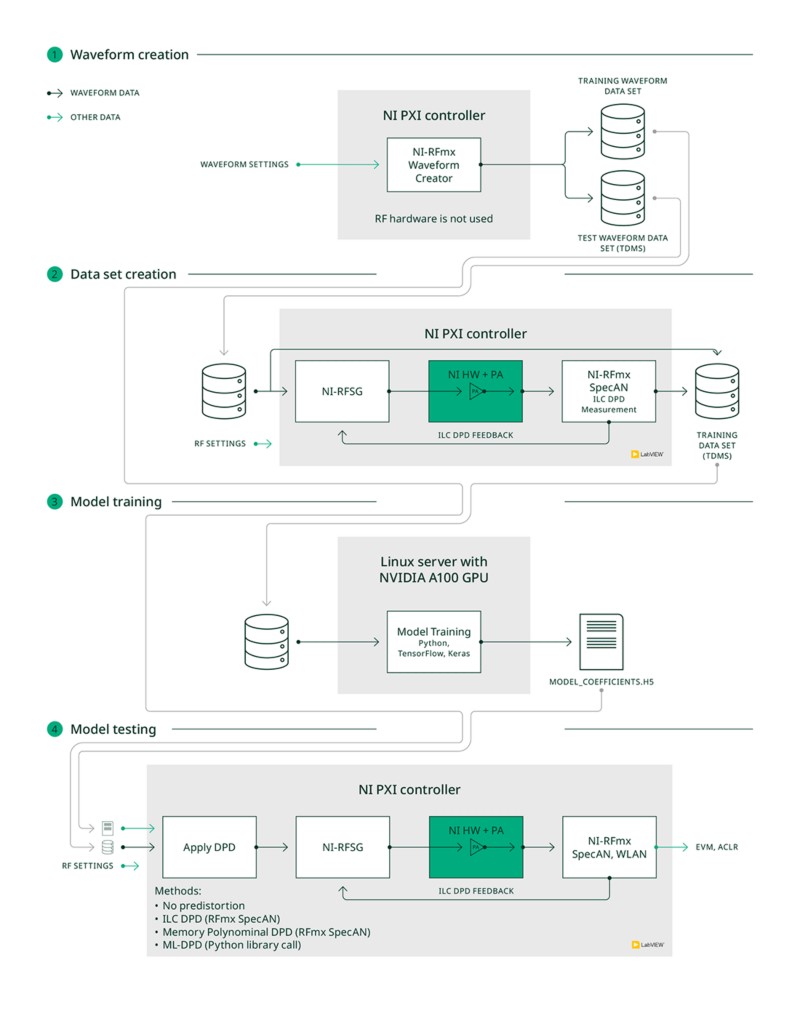
Figure 7. Actions utilisateur de l’application prototype ML-DPD
Étape 1 : créer des données waveform avec NI-RFmx Waveform
Creator permet de générer des waveforms conformes à un standard de communication. Dans notre étude de cas, nous avons utilisé NI-RFmx Waveform Creator for WLAN pour créer des données waveform correspondant à plusieurs trames 802.11ax d’une durée de 1 ms, avec une largeur de bande de canal de 80 MHz. Pour les données utiles (payload), nous avons utilisé différentes séquences de bits pseudo-aléatoires, en faisant varier les ordres de modulation de BPSK à 1024-QAM. Les waveforms sont enregistrées au format TDMS.
Elles constituent les signaux d’entrée non distordus dans nos jeux de données. À partir des paramètres définis par l’utilisateur, le jeu de données waveform est divisé en : a) un jeu de données waveform d’entraînement, b) un jeu de données waveform de test. Par exemple, notre jeu d’entraînement contenait généralement certaines waveforms en BPSK.
Étape 2 : créer un jeu de données d’entraînement à partir d’un amplificateur de puissance réel
L’étape suivante consiste à créer un jeu de données d’entraînement. Pour entraîner le modèle de réseau neuronal, il nous faut à la fois le signal d’entrée non distordu et son signal de sortie idéal correspondant, généré via un PA réel configuré avec des conditions de fonctionnement prédéfinies (fréquence centrale RF, niveau de puissance moyenne en entrée, etc.).
Voici comment le signal de sortie idéal du prédistordeur est calculé pour chaque signal d’entrée non distordu (issu des fichiers waveform TDMS) et pour un ensemble donné de conditions de fonctionnement du PA : Les paramètres RF sont configurés sur NI-RFSG selon les conditions souhaitées du PA ; NI-RFSG génère un signal RF, lu depuis un fichier waveform TDMS du jeu d’entraînement créé à l’étape 1, et l’injecte à l’entrée du PA via le générateur de signaux vectoriels intégré à un NI VST ; Le signal de sortie du PA est capturé par l’analyseur de signaux vectoriels intégré au NI VST, puis mesuré à l’aide de la fonction IDPD (ILC DPD) de NI-RFmx SpecAn ; Cette mesure renvoie un waveform prédistordu que nous enregistrons comme signal de sortie idéal du prédistordeur.
Les données I/Q du waveform, ainsi que les métadonnées associées aux paramètres du signal et aux réglages RF, sont enregistrées dans un fichier de jeu de données d’entraînement au format TDMS.
Ce fichier de jeu de données d’entraînement contient les informations suivantes :
- Données waveform I/Q
- Signal d’entrée non distordu : un signal en bande de base non altéré, dans notre cas un waveform 802.11ax généré à l’étape 1. Il est également possible d’utiliser d’autres waveforms, comme un signal multitonal ou un waveform conforme à un standard de communication sans fil quelconque.
- Signal de sortie idéal du prédistordeur : le waveform calculé à l’aide du contrôle par apprentissage itératif (ILC). Pour cela, nous avons utilisé la mesure IDPD (DPD basée sur ILC) dans NI-RFmx SpecAn.
- Métadonnées (contenus importants avec exemples de valeurs)
- Exemples de configuration du waveform
- Standard : 802.11ax
- Bande passante : 80 MHz
- Ordre de modulation : BPSK
- Longueur de waveform : 1 ms
- Waveform PAPR : - 10,8 dB
- Exemples de configuration du waveform
- Exemples de paramètres RF
- Fréquence centrale RF : 5,5 GHz
- Niveau moyen de puissance en entrée du PA : -10 dBm
Comme mentionné précédemment, un chercheur peut utiliser ce jeu de données pour entraîner n’importe quel modèle de prédistorsion. Il n’est pas nécessaire de répéter le processus de génération du jeu de données d’entraînement sauf si les conditions d’entraînement changent.
Étape 3 : entraîner un modèle
Une fois le jeu de données d’entraînement constitué, l’étape suivante consiste à entraîner le modèle. Le processus employé est illustré dans la figure 8. L’application d’entraînement est écrite en Python, avec les bibliothèques TensorFlow et Keras, et s’exécute sur un serveur Linux équipé d’un GPU NVIDIA A100 pour accélérer la phase d’apprentissage. Le jeu de données d’entraînement est d’abord divisé en ensembles d’entraînement, de validation et de test. Pendant l’entraînement, le modèle reçoit les signaux d’entrée non distordus issus des ensembles d’entraînement et de validation, et prédit les signaux de sortie du prédistordeur correspondants.
Ces derniers sont comparés aux signaux de sortie idéaux du prédistordeur, ce qui permet de calculer les pertes (loss) pour l’entraînement et la validation. La perte d’entraînement est utilisée pour mettre à jour les coefficients du modèle. La perte de validation est surveillée afin d’évaluer la capacité de généralisation du modèle et de détecter un éventuel surapprentissage. La métrique de perte utilisée est l’erreur quadratique moyenne (MSE) entre la sortie prédite et la sortie idéale attendue (le signal de sortie du prédistordeur).
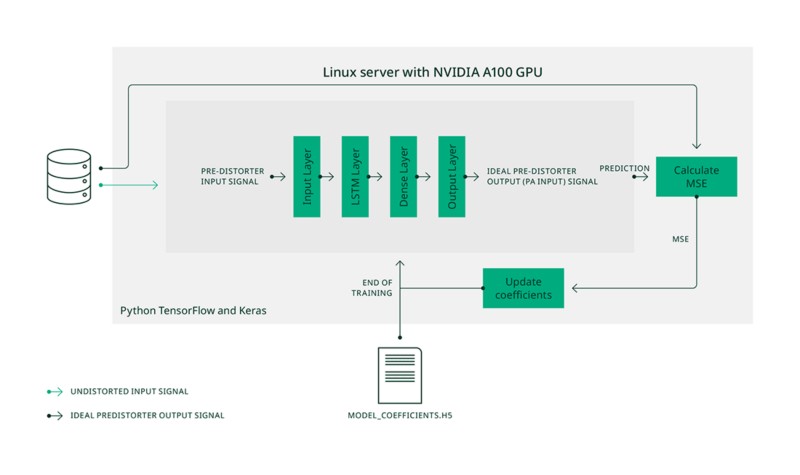
Figure 8. Entraînement du modèle
Lors de nos expériences d’entraînement et de validation, nous avons observé que l’apprentissage était concluant lorsque nous atteignions une perte MSE inférieure à 10-4 et que les courbes de perte pour l’entraînement et la validation convergeaient de manière régulière vers une valeur basse similaire, comme illustré à la figure 9. La sortie finale du processus d’entraînement est un fichier au format H5 contenant les coefficients du modèle entraîné.
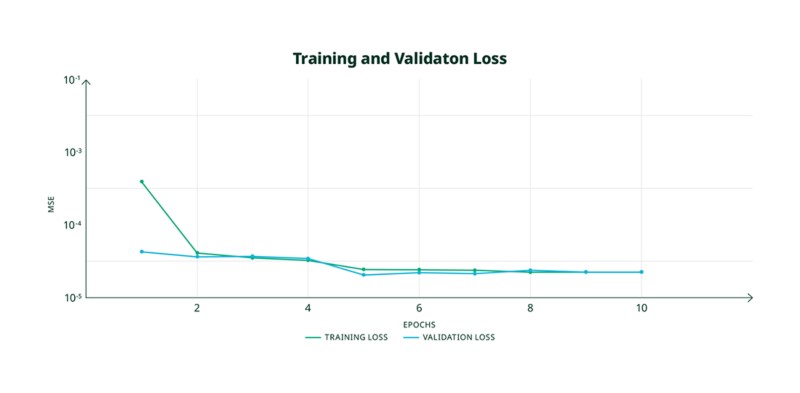
Figure°9. Courbes de perte d’entraînement et de validation attendues
Étape 4 : déployer le modèle pour prédistordre le signal d’entrée d’un PA réel
Le modèle ML-DPD entraîné doit être testé afin de vérifier qu’il fonctionne également avec des données waveform sur lesquelles il n’a pas été entraîné. Pour cela, le modèle est utilisé pour appliquer la prédistorsion sur les données issues du jeu de test avant de générer un signal vers l’amplificateur. Le modèle est appliqué via un appel à une bibliothèque Python depuis LabVIEW, en fournissant en entrée le fichier de coefficients du modèle ainsi que les données waveform. Ses performances sont comparées à celles de la DPD basée sur ILC. En plus de la DPD ILC et ML-DPD, l’application de test peut aussi appliquer des méthodes conventionnelles de prédistorsion, comme la DPD polynomiale à mémoire, afin de comparer les performances du ML-DPD à ces approches classiques. Les performances peuvent être comparées à l’aide de métriques standards comme le RMS EVM et l’ACLR, via NI RFmx SpecAn et RFmx NR ou RFmx WLAN (selon le type de signal).
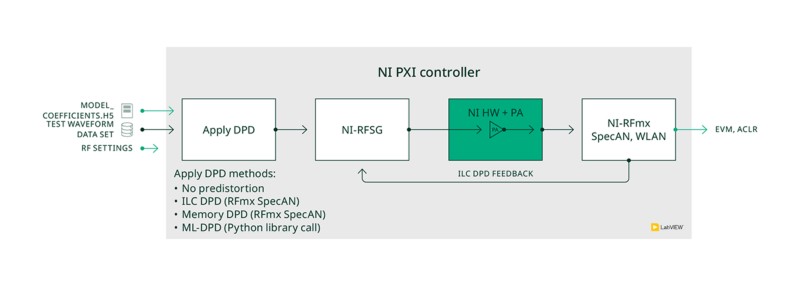
Figure 10. Courbes de perte d’entraînement et de validation attendues
Résultats d’exemple
L’application prototype a été utilisée pour concevoir et tester la ML-DPD avec un amplificateur Wi-Fi TriQuint (carte d’évaluation : TQP887051).


Figure 11. Configuration de test de l’application prototype ML-DPD avec un système PXI (à gauche) et un amplificateur Wi-Fi TriQuint (à droite)
Pour le test, nous avons sélectionné une fréquence centrale de 5,5 GHz et un niveau moyen de puissance en entrée du PA de -8,5 dBm. Les caractéristiques AM-AM du PA à ce point de fonctionnement ont été mesurées à l’aide de NI-RFmx SpecAn, sur une waveform 802.11ax à 80 MHz et 1024-QAM, avec un PAPR d’environ 10,5 dB, comme le montre la figure 11. Le PA présente un gain linéaire d’environ 25,7 dB. Au niveau de puissance d’entrée maximal d’environ 2 dBm, on observe une compression du gain d’environ 3 dB en sortie.
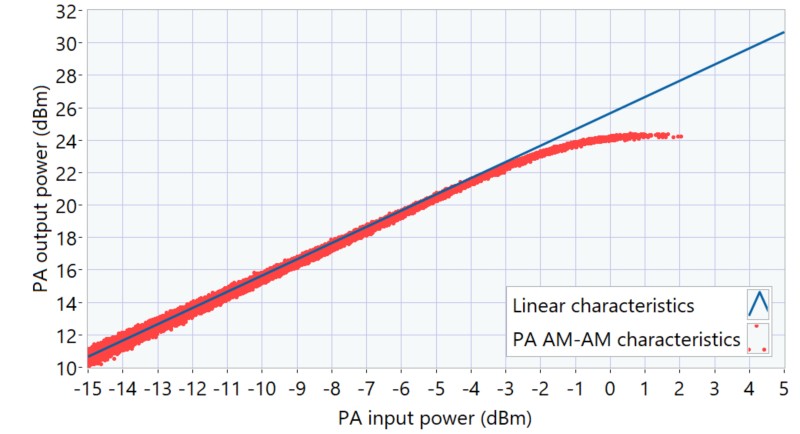
Figure 12. Caractéristiques AM-AM du PA à 5,5 GHz et niveau moyen de puissance en entrée de -8,5 dBm
Nous avons entraîné le modèle à ce point de fonctionnement à l’aide d’un jeu de données contenant 13 trames 802.11ax différentes avec une modulation BPSK. La profondeur mémoire du modèle a été fixée à quatre échantillons, ce qui donne une taille de modèle d’environ 24 000 paramètres. Le jeu de données de validation contenait trois trames 802.11ax avec modulation BPSK. Chaque trame 802.11ax a une durée de 1 ms. La figure 12 présente les courbes de perte observées pendant l’entraînement. Les pertes d’entraînement et de validation observées, d’environ 2 × 10-4, sont jugées acceptables. Nous avons testé différentes valeurs pour la profondeur mémoire, et la valeur quatre s’est révélée adaptée.
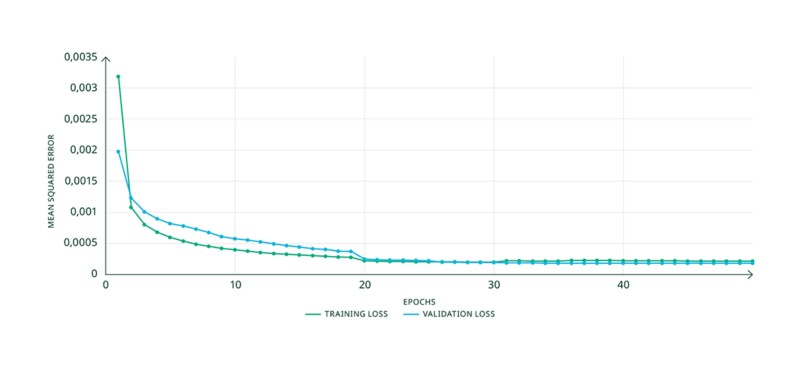
Figure 13. Courbes de perte pour le modèle entraîné
Nous avons ensuite testé le modèle avec différentes données waveform et à divers niveaux moyens de puissance en entrée, allant de -15 dBm à -8,5 dBm, par incréments de 0,25 dB. Pour le résultat de test présenté en figure 13, nous avons utilisé un fichier de données waveform en 1024-QAM issu du jeu de données de test. Il s’agit du même waveform que celui utilisé pour mesurer les caractéristiques AM-AM mentionnées précédemment. Nous avons mesuré le RMS EVM à l’aide de NI-RFmx WLAN pour trois modes de prédistorsion :
- Sans prédistorsion
- DPD basée sur ILC
- ML-DPD
Nous avons comparé les performances de la ML-DPD à celles de la DPD ILC, car le modèle ML-DPD a été entraîné à partir de données issues de la DPD ILC, utilisées comme référence (ground truth). Comme le montre le graphique, les deux approches (ILC DPD et ML-DPD) permettent une nette amélioration de l’EVM par rapport à la mesure effectuée sans aucune prédistorsion. Pour le niveau de puissance d’entrée de -8,5 dBm, qui correspond au point utilisé pendant l’entraînement, la ML-DPD entraînée fournit les mêmes performances EVM que la DPD ILC optimale.
Pour la majorité des autres niveaux de puissance en entrée, les performances EVM de la ML-DPD restent proches (à moins de 1 dB) de celles atteintes avec la DPD ILC. Seule une légère déviation plus marquée de l’EVM, allant jusqu’à 2 dB, est observée entre -10,5 dBm et -9,5 dBm. Cette différence pourrait potentiellement être réduite en intégrant des données d’entraînement supplémentaires provenant de cette plage de puissance.
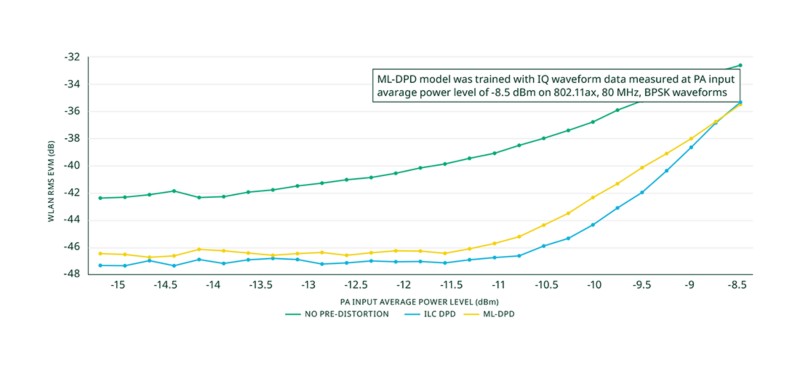
Figure 14. WLAN RMS EVM avec et sans prédistorsion.
Résumé et conclusion
Dans cet article, nous avons montré comment les solutions logicielles et matérielles de NI peuvent être utilisées pour prototyper, valider et évaluer l’utilisation de méthodes d’apprentissage automatique pour la prédistorsion numérique des amplificateurs de puissance. Nous avons utilisé le même système de prototypage pour générer les données d’entraînement et valider les performances d’inférence en les comparant à celles d’autres algorithmes DPD de pointe. Nous avons présenté un exemple d’application d’un réseau neuronal de type LSTM pour la DPD d’un amplificateur Wi-Fi. Les résultats indiquent que, dans ce cas spécifique, les performances de la DPD ML sont proches de la limite inférieure fixée par la DPD ILC, utilisée comme référence lors de l’entraînement du modèle ML.
Il convient de noter que, même si cet exemple est concluant, nous avons également observé des situations dans lesquelles notre modèle DPD ML ne produisait pas les résultats escomptés. L’un des enseignements clés de notre étude est qu’il est toujours essentiel de comparer et d’évaluer les nouveaux modèles DPD basés sur le ML par rapport à d’autres approches de DPD, afin de mieux comprendre les compromis entre efficacité et complexité. Il est important de démontrer, sur des systèmes réalistes, dans quels cas l’utilisation de la DPD ML peut apporter des bénéfices et dans quels contextes les algorithmes DPD traditionnels restent plus adaptés.
Nous pensons que les axes de recherche suivants nécessitent davantage d’investigations et d’innovations :
- Les compromis entre des modèles DPD ML généralisés et plus volumineux, et des modèles plus compacts pouvant être réentraînés et adaptés en cours d’exploitation, ainsi que les stratégies d’entraînement associées.
- Le développement de modèles DPD ML optimisés en performance, capables de fonctionner en temps réel, avec une complexité réduite, sur des plateformes cibles de type FPGA, GPU ou CPU.
- La consommation énergétique du modèle DPD ML sur la plateforme de traitement numérique, afin que la DPD n’annule pas les gains de rendement énergétique obtenus sur le PA.
- Méthodologies de validation et de test intelligentes pour démontrer de manière efficace la fiabilité et la robustesse des modèles DPD basés sur l’apprentissage automatique et les données.
Pour explorer ces questions de recherche, le matériel RF de NI, associé à ses outils logiciels de pointe, constitue une plateforme idéale pour analyser les compromis spécifiques de la DPD ML à prendre en compte dans la conception de systèmes RF plus économes en énergie. Cette démarche contribuera, à terme, à renforcer la confiance dans l’utilisation de technologies d’IA avancées dans des systèmes critiques tels que les réseaux de communication mobile.
Références
1 Sundarum, Meesha. « 3GPP Technology Trends. » 5G Americas, 2024. https://www.5gamericas.org/3gp-technology-trends.
2 Polese, M., Dohler, M., Dressler, F., Erol-Kantarci, M., Jana, R., Knopp, R., Melodia, T., « Empowering the 6G Cellular Architecture with Open RAN. » IEEE Journal on Selected Areas in Communications, novembre 2023.
3 Summerfield, Steve. « How to Make a Digital Predistortion Solution Practical and Relevant. » Microwaves & RF, 2022. https://www.mwrf.com/technologies/embedded/systems/article/21215159/analog-devices-how-to-make-adigital-predistortion-solution-practical-and-relevant.
4 Zhu, Anding, 10 janvier 2023. « Digital Predistortion of Wireless Transmitters Using Machine Learning. » IEEE MTT-S Webinar.
5 Liu, T., Boumaiza, S., et Ghannouchi, F. M., mars 2004. « Dynamic Behavioral Modeling of 3G Power Amplifiers Using Real-Valued Time-Delay Neural Networks. » IEEE Transactions on Microwave Theory and Techniques, 52 (3) : 1025–1033.
6 Luongvinh, Danh et Kwon, Youngwoo, 2005. « Behavioral Modeling of Power Amplifiers Using Fully Recurrent Neural Networks. » IEEE MTT-S International Microwave Symposium Digest : 1979–1982.
7 Rawat, M., Rawat, K., et Ghannouchi, F. M., janvier 2010. « Adaptive Digital Predistortion of Wireless Power Amplifiers/Transmitters Using Dynamic Real-Valued Focused Time-Delay Line Neural Networks. » IEEE Transactions on Microwave Theory and Techniques 58 (1) : 95-104.
8 Hochreiter, S et Schmidhuber, J., novembre 1997. « Long short-term memory. » Neural Computation 9 (8) : 1735–1780.
9 Olah, Christopher. « Understanding LSTM Networks. » Understanding LSTM Networks -- colah’s blog, 27 août 2015. https://colah.github.io/posts/2015-08-Understanding-LSTMs/.
10 Chen, P., Alsahali, S., Alt, A., Lees, J., et Tasker, P. J., 2018. « Behavioral Modeling of GaN Power Amplifiers Using Long Short-Term Memory Networks. » 2018 International Workshop on Integrated Nonlinear Microwave and MillimetreWave Circuits (INMMIC), Brive-la-Gaillarde, France, pp. 1–3.
11 Li, G., Zhang, Y., Li, H., Qiao, W., et Liu, F., 2020. « Instant Gated Recurrent Neural Network Behavioral Model for Digital Predistortion of RF Power Amplifiers. » IEEE Access, vol. 8 : 67474–67483.
12 Kobal, T., Li, Y., Wang, X., et Zhu, A., juin 2022. « Digital Predistortion of RF Power Amplifiers with Phase-Gated Recurrent Neural Networks. » IEEE Transactions on Microwave Theory and Techniques 70 (6) : 3291–3299.
13 Hu, X. et al., août 2022. « Convolutional Neural Network for Behavioral Modeling and Predistortion of Wideband Power Amplifiers. » IEEE Transactions on Neural Networks and Learning Systems 33 (8) : 3923–3937.
14 Brihuega, A., Anttila, L., et Valkama, M., août 2020. « Neural-Network-Based Digital Predistortion for Active Antenna Arrays Under Load Modulation. » IEEE Microwave and Wireless Components Letters 30 (8) : 843–846