Generación de prototipos y evaluación comparativa de la predistorsión digital basada en el aprendizaje automático con el hardware de RF de NI.
Información general
La predistorsión digital (DPD) de los amplificadores de potencia (PA) sigue siendo un área de investigación activa y el aprendizaje automático promete abordar el desafío de los sistemas de comunicación modernos. En este artículo, describimos cómo utilizamos la plataforma de RF de NI e implementamos una aplicación de prototipo para entrenar un modelo DPD basado en aprendizaje automático (ML-DPD) con datos de forma de onda de un PA real, validando el rendimiento de predistorsión de ML-DPD con el PA y comparando el rendimiento con otros algoritmos de última generación. Proporcionamos aprendizajes clave de nuestro trabajo de experimentación y resumimos desafíos y preguntas de investigación para usar DPD basado en ML en implementaciones prácticas.
Contenido
- AI/ML en comunicación inalámbrica y RF
- Descripción general de la predistorsión digital
- Predistorsión digital basada en el aprendizaje automático
- Aplicación de generación de prototipos y evaluación comparativa de ML-DPD
- Resultados del muestreo
- Resumen y conclusiones
- Referencias
- Próximos pasos
AI/ML en comunicación inalámbrica y RF
Debido a los enormes avances en el área de la inteligencia artificial (IA) y el aprendizaje automático (ML) en los últimos años, hay nuevas formas de resolver problemas desafiantes en muchas industrias. En el ámbito inalámbrico, el uso de IA/ML es uno de los candidatos tecnológicos más prometedores que se debate actualmente para proporcionar nuevos servicios y mejorar las redes móviles. 1 Entre otros, la IA/ML puede ayudar a los operadores de redes móviles (MNO) a mejorar la eficiencia de sus redes y reducir los costos operativos, uno de los principales objetivos de los MNO. Estas mejoras podrían significar un uso más eficiente del espectro a través de una asignación más inteligente de recursos en el dominio del tiempo, la frecuencia y espacial, o mejores esquemas de compensación de interferencias. Además, el uso de AI/ML también podría permitir mejorar la eficiencia energética para abordar uno de los principales factores de costos de las estaciones base. Por ejemplo, formas más inteligentes de encender y apagar estaciones base según las necesidades podrían crear un uso más eficiente de amplificadores de potencia.
Si bien la IA/ML ya se está utilizando con éxito a nivel de la red, existen muchos más desafíos al utilizar la IA/ML en las capas inferiores, como la capa de RF, la capa física (PHY) o la capa MAC. Las estrictas limitaciones de tiempo en estas capas inferiores significa que es más difícil desarrollar e implementar algoritmos robustos y confiables basados en IA/ML que proporcionan ganancias significativas sobre los métodos tradicionales. 2 Por lo tanto, esta área todavía está en su fase de investigación para comprender las diferentes limitantes para utilizar con éxito la IA/ML en áreas donde tiene sentido y demostrar que esos algoritmos de IA/ML son robustos y confiables en implementaciones de redes reales. Básicamente, hay que demostrar que el uso de IA/ML muestra claras ventajas frente a los enfoques tradicionales para justificar nuevas inversiones.
Las actividades de investigación de IA/ML de hoy en día sobre capas de RF/PHY/MAC de sistemas de comunicaciones inalámbricas incluyen las siguientes áreas:
- RF—Predistorsión digital (DPD) basada en ML para mejorar la eficiencia de los amplificadores de potencia y ahorrar energía.
- PHY—Estimación de canales basada en ML y detección de símbolos para mejorar la eficiencia espectral, utilizando menos símbolos piloto o ninguno, así como para mejorar la eficiencia energética al tener la misma calidad de transmisión a una relación señal/ruido más baja.
- MAC—Gestión de haces basada en ML para mejorar la adquisición y el seguimiento de haces con el objetivo de dirigir la energía de una matriz de antenas en la dirección de un usuario. Con eso, el espectro se puede utilizar de manera más eficiente sirviendo a más usuarios en una celda. Además, se puede ahorrar energía para adaptar la relación señal-ruido en el receptor a las necesidades reales de calidad de servicio.
En otra nota técnica de NI, describimos un framework para crear prototipos y comparar un receptor neuronal en tiempo real utilizando dispositivos NI SDR. En esta nota técnica, describimos un caso de estudio de cómo crear prototipos y comparar algoritmos de ML para la predistorsión digital de amplificadores de potencia utilizando hardware de RF de NI. Proporcionamos una breve descripción general de algunas redes neuronales típicas que se han investigado para DPD. También describimos cómo implementamos un prototipo de aplicación para entrenar un modelo ML-DPD con datos de forma de onda de un PA real, validando su rendimiento de predistorsión con el PA y comparando el rendimiento con otros algoritmos de última generación. Al final, proporcionamos aprendizajes clave de nuestro trabajo de experimentación y resumimos los desafíos y preguntas de investigación para usar DPD basada en ML en implementaciones prácticas.
Descripción general de la predistorsión digital
Es bien sabido que los amplificadores de potencia (PA) son más eficientes cuando operan en su región no lineal. Lamentablemente, en esta región el PA genera emisiones fuera de banda no deseadas por intermodulación causada por características no lineales del PA. La predistorsión digital se aplica generalmente a la forma de onda del transmisor para compensar las distorsiones. La compensación, o la predistorsión, aplica la inversa de la no linealidad de un PA en banda base digital, por lo que la respuesta combinada de DPD y el PA vuelve a ser lineal. La gráfica 1 ilustra este sistema de compensación. Como resultado, el DPD permite a un PA operar en una región no lineal con mayor eficiencia energética sin perder linealidad.
Las velocidades de datos siempre exigentes requieren más ancho de banda que está específicamente disponible a frecuencias más altas que generalmente requieren arreglos de antenas para dirigir la energía y superar la alta pérdida de trayectoria. Específicamente para los PAs diseñados para operar en estas condiciones, la DPD se vuelve cada vez más difícil por las siguientes razones:
- Comportamiento no estático de los PAs donde el modelo subyacente cambia para las condiciones dinámicas de operación
- Aumento de la complejidad de las no linealidades del PA cuando los modelos basados en la serie Volterra ya no son adecuados
Para hacer frente a los desafíos mencionados anteriormente para los sistemas de comunicación modernos, se necesitan enfoques innovadores para la DPD. El aprendizaje automático es un enfoque que está siendo investigado activamente por la industria y la academia, que describiremos en la siguiente sección.
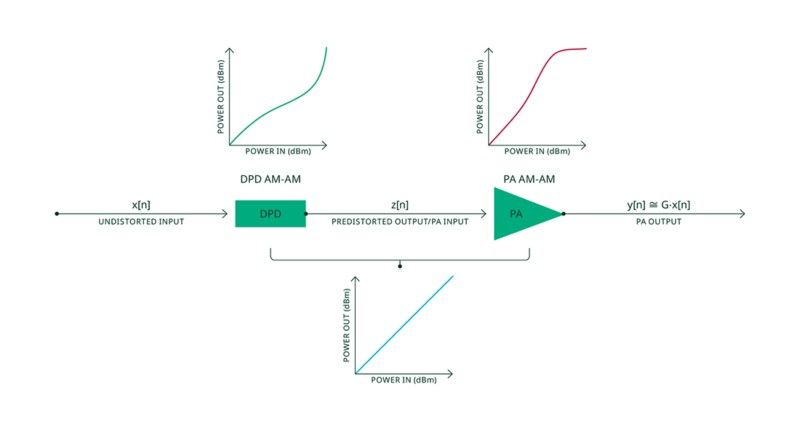
Figura 1. El principio de predistorsión digital
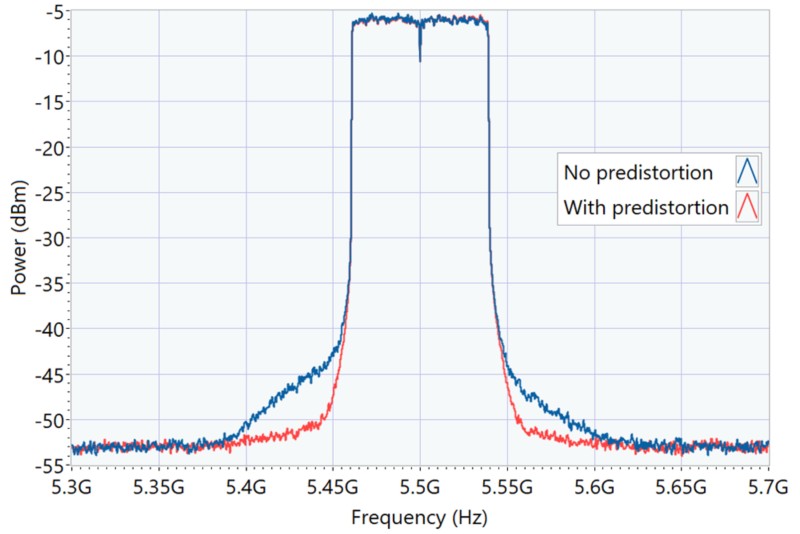
Figura 2. Mejora espectral de fugas debido a la DPD
La Figura 2 muestra un ejemplo de mejora en la fuga espectral por predistorsión comparando la señal de salida de un PA Wi-Fi con y sin aplicar predistorsión digital. El principal desafío para la DPD es estimar la no linealidad del PA utilizado, lo que significa estimar el modelo de PA subyacente. Tradicionalmente, para las no linealidades sin memoria, se ha utilizado el enfoque de tablas de búsqueda estáticas basadas en distorsiones AM/AM y AM/PM medidas. Para lidiar con las no linealidades con la memoria, generalmente se usan modelos basados en la serie Volterra como el modelo polinomial de memoria (MPM) y el modelo polinomial de memoria generalizada (GMP).
Predistorsión digital basada en el aprendizaje automático
Las redes neuronales han sido investigadas para su uso en el modelado conductual y la predistorsión digital debido a su capacidad para modelar sistemas no lineales, como un amplificador de potencia que tiene un comportamiento no lineal con efectos de memoria no lineales.
Hace un par de décadas, un equipo propuso 5 un modelo de red neuronal de retardo de tiempo de valor real (RVTDNN) basado en una estructura de perceptrón multicapa (MLP) para el modelado conductual de amplificadores de potencia 3G. Utilizó líneas de retraso tomadas en componentes en fase (I) y en cuadratura de fase (Q) de la señal para modelar los efectos de memoria a corto plazo del PA. Se propuso una red neuronal totalmente recurrente (FRNN)6 para el modelado conductual de PAs para sistemas de comunicación celular 3G con fuertes efectos de memoria junto con alta no linealidad. Utiliza señales complejas como entrada con pesos y sesgos complejos. La predistorsión digital de amplificadores de potencia usando redes neuronales fue ampliamente investigada y validada para señales WCDMA, 7 que propuso una red neuronal de retraso de tiempo enfocada de valor real (RVFTDNN), que evita el cálculo de gradientes complejos.
Las redes neuronales recurrentes (RNN) tienen la capacidad inherente de modelar los efectos de la memoria, la situación en la que la salida de corriente depende no solo de la entrada de corriente, sino también de entradas pasadas. Sin embargo, las RNN tienen dificultades para captar los efectos de memoria a largo plazo causados por la desaparición de gradientes. Se propusieron redes de memoria a corto plazo (LSTM) para abordar la cuestión de la desaparición de gradientes en las RNN8.
Las redes LSTM emplean diferentes tipos de puertas para controlar mejor en qué medida la información pasada y nueva impacta los estados de memoria de la red. 9 Para el modelado conductual de PAs GaN con efectos de memoria a largo plazo, un equipo estudió 10 el uso de redes LSTM para trabajar en torno a la limitación de FRNN. 7 Otras versiones mejoradas u optimizadas de redes basadas en RNN como las redes bidireccionales LSTM (BiLSTM) y unidades periódicas cerradas (GRU) se describen con el propósito de la predistorsión digital 11,12 y referencias en ellas. Recientemente, se exploraron las redes neuronales convolucionales (CNN) para el modelado conductual y la predistorsión de los PAs.13
También se han propuesto redes neuronales para evitar la actualización continua de parámetros de predistorsión digital en sistemas de MIMO masivo con arreglos de antenas activas, que sufren modulación de carga dependiente de haz. 14 Para este caso de estudio, se optó por implementar una red neuronal basada en LSTM para DPD.
La Figura 3 muestra todas las capas de la red neuronal implementada. La red obtiene muestras de la señal compleja en el dominio del tiempo no distorsionada x[n] como entrada y proporciona muestreos para la señal compleja en el dominio del tiempo predistorsionada z[n] en la salida. En un paso de tiempo, la entrada a la capa LSTM son los componentes en fase y en cuadratura de fase i, q de los M muestreos de señal de entrada actuales y pasadas, donde M es la profundidad de memoria.
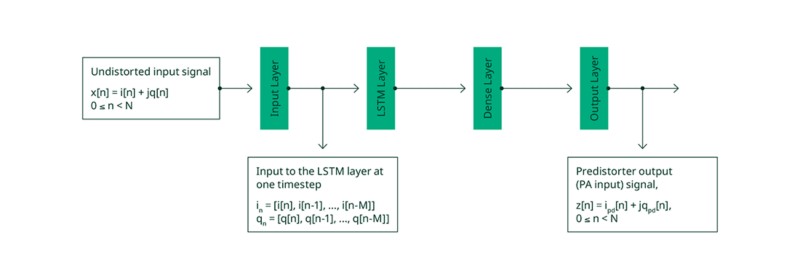
Figura 3. Arquitectura de modelos
La red neuronal debe entrenarse en la funcionalidad de DPD objetivo utilizando un conjunto de datos de entrenamiento durante la etapa de aprendizaje (entrenamiento). Las arquitecturas de aprendizaje comunes para un modelo DPD podrían ser una arquitectura de aprendizaje directo (DLA), una arquitectura de aprendizaje indirecto (ILA) o una arquitectura basada en el control de aprendizaje iterativo (ILC). Para nuestro caso de estudio, elegimos ILC como fuente de datos de entrenamiento, ya que proporciona una señal de entrada predistorsionada de PA óptima que linealiza al PA.
El DPD basado en ILC es útil como punto de referencia para evaluar el rendimiento de cualquier esquema de DPD.
La Figura 4 muestra la arquitectura de aprendizaje para que ILC compute iterativamente una señal de salida pre-distorsionadora, z[n], que también es la señal de entrada al PA, dada una señal de entrada no distorsionada, x[n]. Después de suficientes iteraciones, se puede suponer que la señal de salida pre-distorsionadora final calculada es la señal de salida pre-distorsionadora ideal y la señal de entrada al PA ideal, zideal [n]
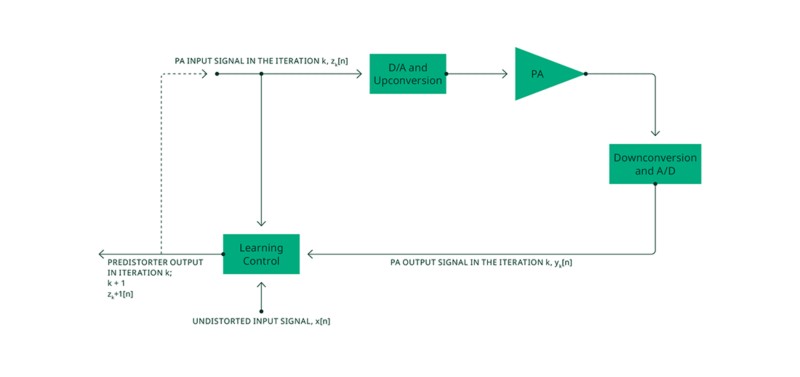
Figura 4. Arquitectura de aprendizaje: Control de aprendizaje iterativo
Uno o más pares de una señal de entrada no distorsionada y su correspondiente señal de salida pre-distorsionadora ideal pueden usarse para entrenar o ajustar parámetros de cualquier modelo DPD, incluyendo los modelos polinomiales de memoria generalizada tradicionales, o como en nuestro caso, un modelo de red neuronal. Durante el proceso de entrenamiento, las señales de salida pre-distorsionadoras ideales actúan como verdad fundamental para las señales de salida objetivo que el modelo DPD debe aprender a generar para las señales de entrada no distorsionadas respectivas. Este proceso se muestra en la Figura 5.
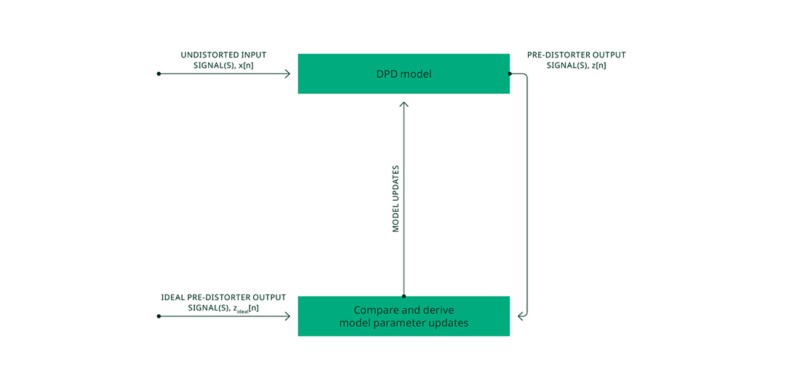
Figura 5. Entrenamiento del modelo DPD
Aplicación de generación de prototipos y evaluación comparativa de ML-DPD
Creamos un prototipo de aplicación para estudiar todo el flujo de trabajo de una implementación de DPD basada en aprendizaje automático.
La aplicación se ejecuta en un controlador PXI en un chasis NI PXI utilizando un transceptor vectoriales de señales (VST) NI PXI para generar y analizar señales de RF y una unidad de medida de fuente NI PXI para proporcionar potencia DC y controlar líneas digitales al PA. En la figura 6 se muestra un diagrama de bloques de la configuración de prueba utilizada.
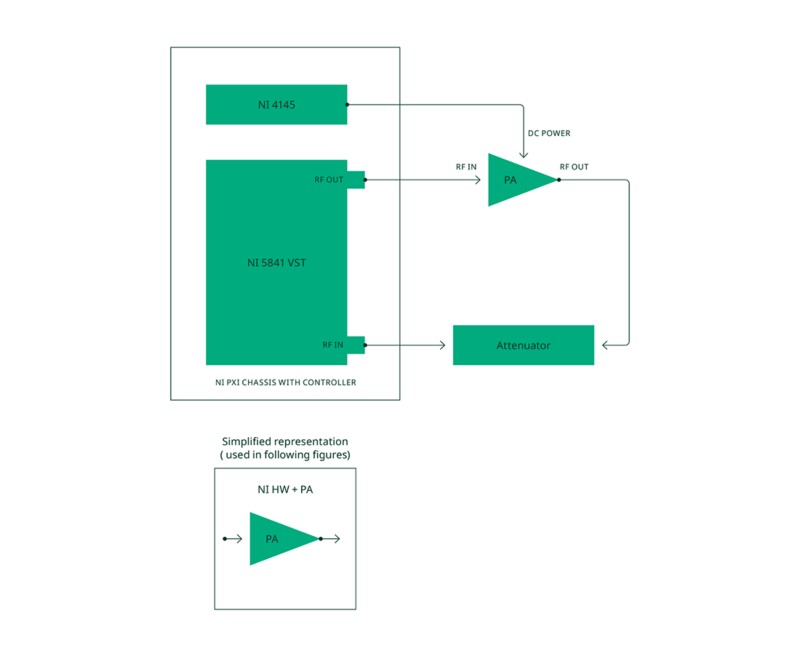
Figura 6. Configuración de prueba que muestra conexiones de hardware
La aplicación se utiliza para realizar estos pasos:
- Crear datos de forma de onda que se utilizarán para entrenamiento y pruebas.
- Crear un conjunto de datos de entrenamiento usando un PA real.
- Utilizar el conjunto de datos de entrenamiento para entrenar un modelo de red neuronal.
- Implementar el modelo de red neuronal entrenado para predistorsionar la entrada a un PA real.
La figura 7 muestra estas acciones de usuario. En las secciones siguientes se explican en detalle. Excepto para el entrenamiento del modelo de red neuronal, la aplicación está escrita en NI LabVIEW. Utiliza el software NI RFmx para realizar medidas de RF estándar en el PA utilizando un transceptor vectorial de señales (VST) de NI. Utiliza el NI RFmx Waveform Creator para crear archivos de forma de onda. El entrenamiento del modelo de red neuronal se implementa en Python utilizando las bibliotecas TensorFlow y Keras. Para una ejecución más rápida, el entrenamiento se ejecuta en un servidor Linux con una GPU NVIDIA.
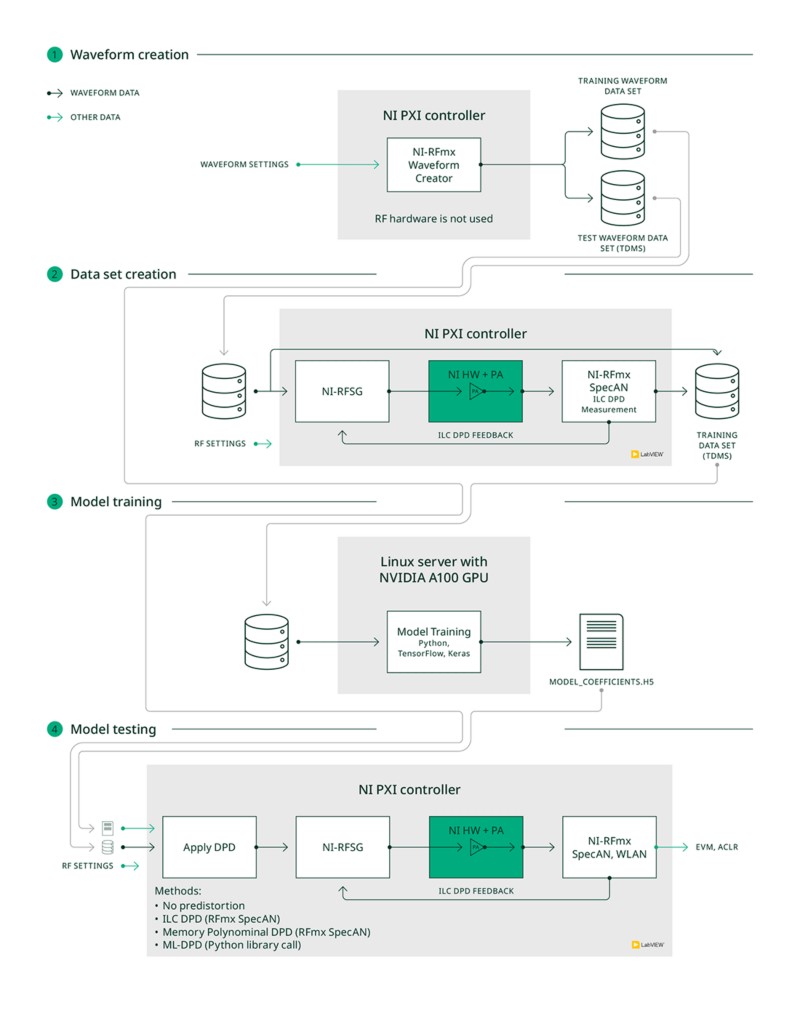
Figura 7. Acciones del usuario de la aplicación de prototipo de ML-DPD
Step 1: Crear datos de forma de onda con NI-RFmx Waveform
Creator se puede utilizar para crear formas de onda compatibles con un estándar de comunicación. Para nuestro caso de estudio, utilizamos NI-RFmx Waveform Creator for WLAN para crear datos de forma de onda para múltiples marcos 802.11ax de 1 ms de longitud con un ancho de banda de canal de 80 MHz. Para los datos de carga útil, utilizamos diferentes secuencias de bits de datos pseudo aleatorias y variamos las órdenes de modulación de BPSK a 1024-QAM. Las formas de onda se almacenan en un formato de archivo TDMS.
Estas formas de onda forman las señales de entrada no distorsionadas en nuestros conjuntos de datos. En base a las entradas especificadas por el usuario, el conjunto de datos de forma de onda se divide en a) un conjunto de datos de forma de onda de entrenamiento y b) un conjunto de datos de forma de onda de prueba. Por ejemplo, nuestro conjunto de datos de forma de onda de entrenamiento normalmente contenía algunas de las formas de onda BPSK.
Step 2: Crear un conjunto de datos de entrenamiento usando un PA real
El siguiente paso es crear un conjunto de datos de entrenamiento. Para entrenar el modelo NN, necesitamos la señal de entrada no distorsionada y su correspondiente señal de salida pre-distorsionadora ideal, calculada usando un PA real en un conjunto predeterminado de condiciones de operación del PA, como la frecuencia central de RF y el nivel de potencia promedio de entrada.
Para cada una de las señales de entrada no distorsionadas leídas de los archivos TDMS de forma de onda y las condiciones de operación PA, así es como se calcula la señal de salida pre-distorsionadora ideal: Los ajustes de RF se configuran en NI-RFSG según la condición de operación del PA deseada. NI-RFSG genera una señal de RF, leída desde un archivo TDMS de forma de onda del conjunto de datos de forma de onda de entrenamiento creado en el Paso 1, en la entrada del PA usando el generador vectorial de señales dentro de un NI VST. La señal de salida del PA es adquirida por el analizador vectorial de señales dentro de un NI VST y medida usando la medida IDPD (ILC DPD) de NI-RFmx SpecAn. La medida devuelve una forma de onda predistorsionada, que registramos como la señal de salida ideal pre-distorsionadora.
Los datos de forma de onda I/Q junto con los metadatos asociados a los ajustes de la señal y RF se registran en un archivo de conjunto de datos de entrenamiento de un formato TDMS.
El archivo del conjunto de datos de entrenamiento contiene la siguiente información:
- Datos de forma de onda I/Q
- Señal de entrada no distorsionada: una señal de banda base no alterada, que en nuestro caso es una forma de onda 802.11ax creada en el Paso 1. Es posible utilizar otras formas de onda como una señal de múltiples tonos o una forma de onda compatible con cualquier estándar de comunicación inalámbrica
- Señal de salida ideal pre-distorsionadora: la forma de onda calculada usando el control de aprendizaje iterativo (ILC). Para ello, utilizamos la medida DPD basada en ILC (IDPD) en NI - RFmx SpecAn.
- Metadatos (contenidos importantes con valores de ejemplo)
- Ejemplos de configuración de forma de onda
- Estándar: 802.11ax
- Ancho de banda: 80 MHz
- Orden de modulación: BPSK
- Longitud de forma de onda: 1 ms
- Forma de onda PAPR: 10.8 dB
- Ejemplos de configuración de forma de onda
- Ejemplos de ajustes de RF
- Frecuencia central de RF: 5.5 GHz
- Nivel medio de potencia de entrada PA: -10 dBm
Como se mencionó anteriormente, un investigador podría usar este conjunto de datos para entrenar cualquier modelo para el pre-distorsionador. No será necesario repetir el proceso de adquisición del conjunto de datos de entrenamiento a menos que se produzca un cambio en las condiciones de entrenamiento
Step 3: Entrenar un modelo
Después de tener un conjunto de datos de entrenamiento, el siguiente paso es entrenar el modelo. El proceso utilizado se muestra en la Figura 8. La aplicación de entrenamiento está escrita en Python usando las bibliotecas TensorFlow y Keras y se ejecuta en un servidor Linux con una GPU NVIDIA A100 para velocidades de entrenamiento más rápidas. El conjunto de datos de forma de onda de entrenamiento se divide primero en conjuntos de datos de entrenamiento, validación y prueba. Durante el entrenamiento, el modelo se alimenta de las señales de entrada no distorsionadas de los conjuntos de datos de entrenamiento y validación, y predice las respectivas señales de salida pre-distorsionadoras.
Estos últimos se comparan con las señales de salida ideales pre-distorsionadoras y relacionadas, se calcula la respectiva pérdida de entrenamiento y validación. La pérdida de entrenamiento se utiliza para actualizar los coeficientes del modelo. La pérdida de validación es monitoreada para evaluar si el modelo generaliza bien y para detectar sobreajustes. La métrica de pérdida que usamos es el error cuadrático medio (MSE) entre la salida del modelo predicha y la deseada ideal (la salida ideal pre-distorsionadora).
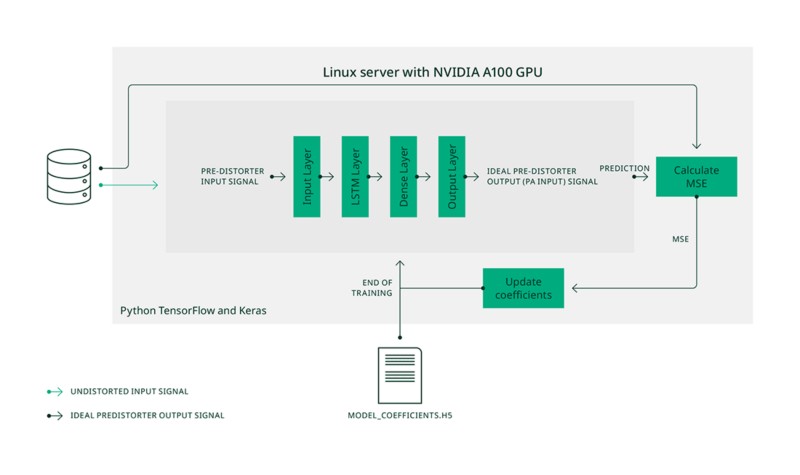
Figura 8. Entrenamiento del modelo
Durante nuestros experimentos de entrenamiento y validación observamos que el entrenamiento fue exitoso cuando alcanzamos valores de pérdida de MSE por debajo de 10-4 y las curvas de pérdida de entrenamiento y validación convergen suavemente hacia un valor similarmente bajo, como se muestra en la Figura 9. El resultado final del proceso de entrenamiento es un archivo H5 que contiene los coeficientes del modelo entrenado.
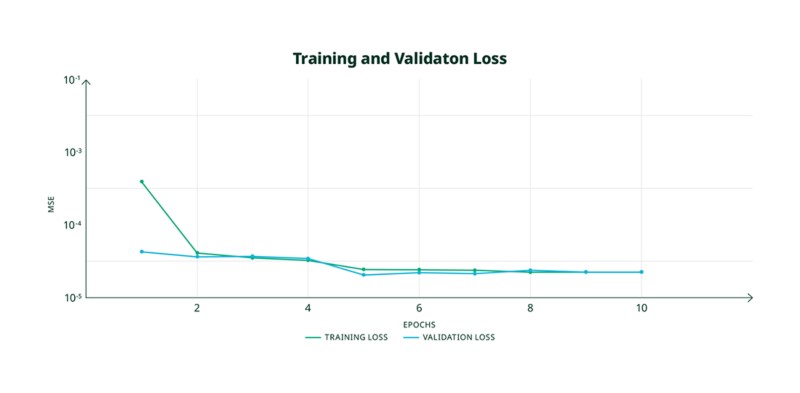
Figura 9. Curvas de pérdida de entrenamiento y validación deseadas
Paso 4: Implementar el modelo para predistorsionar la entrada a un PA real
El modelo ML-DPD entrenado debe probarse para verificar que también puede funcionar para datos de forma de onda en los que el modelo no ha sido entrenado. Para esto, el modelo entrenado se utiliza para aplicar DPD en los datos de forma de onda del conjunto de datos de forma de onda de prueba antes de generar una señal en el PA. El modelo se aplica mediante una llamada a la biblioteca Python desde LabVIEW pasando el archivo de coeficientes del modelo y los datos de forma de onda como entradas. Su rendimiento se compara con ILC DPD. Junto con ILC-DPD y ML-DPD, la aplicación de prueba también puede aplicar métodos convencionales de DPD, como DPD polinomial de memoria para comparar el rendimiento de ML-DPD con ellos. El rendimiento se puede comparar en términos de métricas estándares como RMS EVM y ACLR usando NI RFmx SpecAn y RFmx NR o RFmx WLAN (según el tipo de señal).
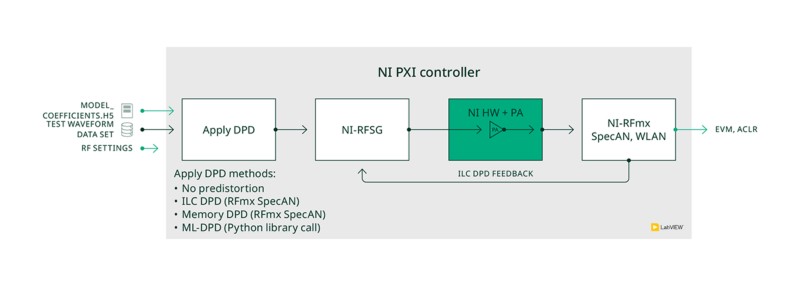
Figura 10. Curvas de pérdida de entrenamiento y validación deseadas
Resultados del muestreo
La aplicación de prototipo se utilizó para diseñar y probar ML-DPD para un PA TriQuint Wi-Fi (tarjeta de evaluación: TQP887051).


Figura 11. Configuración de prueba para la aplicación de prototipo ML-DPD con un sistema PXI (izquierda) y un PA Wi-Fi TriQuint (derecha)
Para las pruebas, seleccionamos la frecuencia central de 5.5 GHz y el nivel de potencia promedio de entrada PA de -8.5 dBm. Las características AM-AM del PA en este punto de operación se midieron utilizando NI-RFmx SpecAn en una forma de onda 802.11ax, 80 MHz, 1024-QAM de aproximadamente PAPR 10.5 dB se muestra en la Figura 11. El PA muestra una ganancia lineal de alrededor de 25.7 dB. En el nivel de potencia de entrada pico de alrededor de 2 dBm, la salida del PA muestra una compresión de ganancia de alrededor de 3 dB.
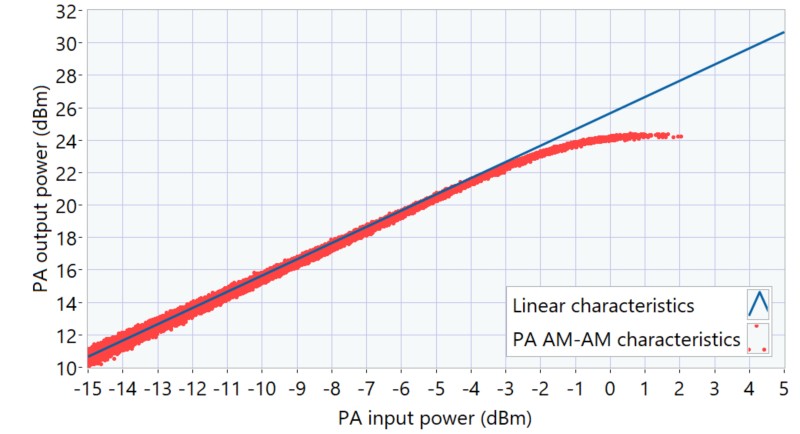
Figura 12. Características AM-AM del PA a 5.5 GHz y nivel de potencia medio de entrada de -8.5 dBm.
Entrenamos el modelo en este punto de operación con un conjunto de datos de entrenamiento que contenía trece marcos 802.11ax diferentes con esquema de modulación BPSK. La profundidad de la memoria del parámetro del modelo se estableció en cuatro muestreos, lo que resultó en un tamaño del modelo de alrededor de 24,000 parámetros. El conjunto de datos de validación contenía tres marcos 802.11ax con esquema de modulación BPSK. Cada marco 802.11ax tiene una longitud de 1 ms. La Figura 12 muestra las curvas de pérdida observadas durante el entrenamiento. Las pérdidas de entrenamiento y validación observadas de alrededor de 2×10-4 son aceptables. Probamos diferentes valores para la profundidad de la memoria y el valor de cuatro se encontró adecuado.
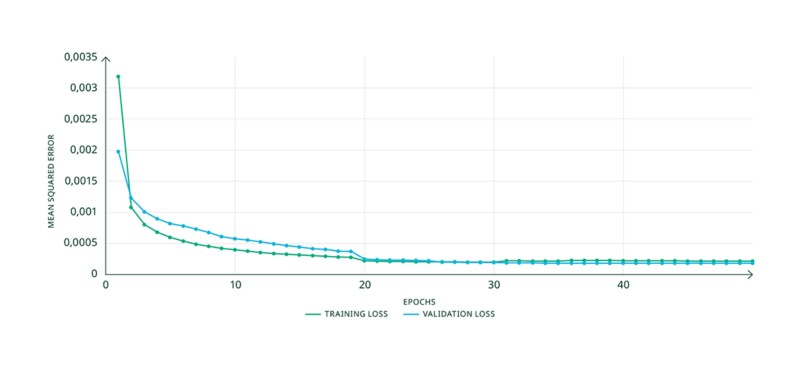
Figura 13. Curvas de pérdida para el modelo entrenado
Luego probamos el modelo con diferentes datos de forma de onda y a diferentes niveles de potencia promedio de entrada que varían de -15 dBm a -8.5 dBm en pasos de 0.25 dB. Para el resultado de prueba de ejemplo en la Figura 13, utilizamos un archivo de datos de forma de onda 1024-QAM del conjunto de datos de prueba. Esta es la misma forma de onda que se utilizó para medir las características AM-AM mostradas anteriormente. Medimos RMS EVM usando NI-RFmx WLAN para tres modos de predistorsión:
- Sin predistorsión
- ILC-DPD
- ML-DPD
Comparamos el rendimiento de ML-DPD con el de ILC-DPD, porque ML-DPD fue entrenado con datos de ILC-DPD que actúan como verdad fundamental. Como se ve en la gráfica, tanto ILC-DPD como ML-DPD muestran una mejora significativa en EVM en comparación con EVM medida sin ninguna predistorsión. Para el nivel de potencia de entrada de -8.5 dB, que se utilizó durante el entrenamiento, el ML-DPD entrenado proporciona el mismo rendimiento EVM que el DPD ILC óptimo.
Para la mayoría de los otros niveles de potencia de entrada, el rendimiento de la EVM ML-DPD está cerca (dentro de 1 dB) de los valores alcanzados con ILC-DPD. Solo para el rango de potencia de entrada de -10.5 dBm a -9.5 dBm, vemos una desviación EVM ligeramente más fuerte de hasta 2 dB entre ML-DPD y la ILC-DPD óptima, que potencialmente podría reducirse aún más incorporando datos de entrenamiento adicionales de estos niveles de potencia en el proceso de entrenamiento.
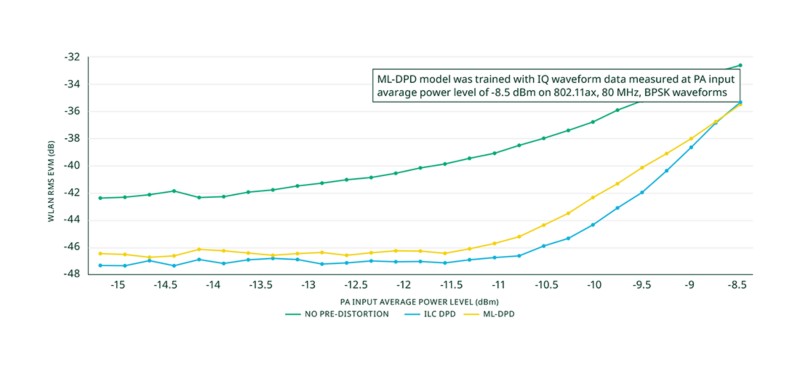
Figura 14. WLAN RMS EVM con y sin predistorsión.
Resumen y conclusiones
En este artículo, mostramos cómo el software y el hardware de NI se pueden utilizar para crear prototipos, validar y comparar el uso de enfoques de aprendizaje automático para la predistorsión digital de amplificadores de potencia. Utilizamos el mismo sistema de generación de prototipos para crear datos de entrenamiento y validar el rendimiento de inferencia frente a otros algoritmos DPD de última generación. Mostramos un ejemplo de resultado para aplicar una red neuronal basada en LSTM para el DPD de un PA Wi-Fi. Los resultados muestran que para este ejemplo específico, el rendimiento del DPD de ML está cerca del límite inferior dado por el DPD de ILC que utilizamos como referencia para el entrenamiento del modelo de ML.
Vale la pena señalar que, si bien el resultado de este ejemplo se ve bien, durante nuestros estudios también encontramos situaciones en las que nuestro modelo de DPD de ML de ejemplo no se desempeñó como se esperaba. Un aprendizaje clave de nuestra investigación es que siempre es importante evaluar y comparar los nuevos modelos de DPD de ML con otros enfoques de DPD para comprender mejor las ventajas y desventajas entre eficiencia y complejidad. Es importante probar en sistemas realistas donde el uso de ML-DPD puede conducir a beneficios y donde los algoritmos tradicionales de DPD son más adecuados.
Creemos que las siguientes áreas necesitan más investigación e innovación:
- Ventajas y desventajas entre los modelos más grandes de ML DPD generalizada frente a los modelos más pequeños que se re-entrenan y adaptan durante la operación y las estrategias de entrenamiento correspondientes.
- Modelos ML DPD de baja complejidad, con capacidad en tiempo real y rendimiento optimizado para plataformas de destino basadas en FPGA, GPU o CPU.
- Bajo consumo de energía del algoritmo ML-DPD en la plataforma de procesamiento digital para que DPD no reduzca el ahorro de energía del PA.
- Validación inteligente y metodologías de prueba para probar eficientemente la fiabilidad y robustez de los modelos de ML DPD basados en datos.
Para investigar esas preguntas de investigación, el hardware de RF de NI descrito con su hardware y software de vanguardia puede ayudarlo a comprender las compensaciones específicas de ML DPD que deben considerarse para el diseño de sistemas de RF más eficientes energéticamente. Esta consideración también generará más confianza en el uso de tecnologías avanzadas de IA en sistemas tan críticos como las redes de comunicaciones móviles.
Referencias
1 Sundarum, Meesha. “Tendencias de la tecnología 3GPP.” 5G Americas, 2024. https://www.5gamericas.org/3gp-technology-trends.
2 Polese, M., Dohler, M., Dressler, F., Erol-Kantarci, M., Jana, R., Knopp, R., Melodia, T., “Impulsando la arquitectura celular 6G con RAN abierta.” IEEE Journal on Selected Areas in Communications, noviembre 2023.
3 Summerfield, Steve. “How to Make a Digital Predistortion Solution Practical and Relevant.” Microondas & RF, 2022. https://www.mwrf.com/technologies/embedded/systems/article/21215159/analog-devices-how-to-make-adigital-predistortion-solution-practical-and-relevant.
4 Zhu, Anding, 10 de enero de 2023. “Digital Predistortion of Wireless Transmitters Using Machine Learning.” Seminario web IEEE MTT-S.
5 Liu, T., Boumaiza, S. y Ghannouchi, F. M., marzo 2004. “Dynamic Behavioral Modeling of 3G Power Amplifiers Using Real-Valued Time-Delay Neural Networks.” IEEE Transactions on Microwave Theory and Techniques, 52 (3): 1025–1033
6 Luongvinh, Danh y Kwon, Youngwoo, 2005. “Behavioral Modeling of Power Amplifiers Using Fully Recurrent Neural Networks.” IEEE MTT-S International Microwave Symposium Digest: 1979–1982
7 Rawat, M., Rawat, K. y Ghannouchi, F. M., enero 2010. “Adaptive Digital Predistortion of Wireless Power Amplifiers/Transmitters Using Dynamic Real-Valued Focused Time-Delay Line Neural Networks.” IEEE Transactions on Microwave Theory and Techniques 58 (1): 95-104.
8 Hochreiter, S y Schmidhuber, J., noviembre 1997. “Long short-term memory.” Neural Computation 9 (8): 1735–1780.
9 Olah, Christopher, “Understanding LSTM Networks.” Understanding LSTM Networks -- colah’s blog, 27 de agosto de 2015. https://colah.github.io/posts/2015-08-Understanding-LSTMs/.
10 Chen, P., Alsahali, S., Alt, A., Lees, J. y Tasker, P. J., 2018. “Behavioral Modeling of GaN Power Amplifiers Using Long Short-Term Memory Networks.” 2018 International Workshop on Integrated Nonlinear Microwave and MillimetreWave Circuits (INMMIC), Brive La Gaillarde, Francia, 2018, págs. 1–3.
11 Li, G., Zhang, Y., Li, H., Qiao, W., y Liu, F., 2020. “Instant Gated Recurrent Neural Network Behavioral Model for Digital Predistortion of RF Power Amplifiers.” IEEE Access, vol. 8: 67474–67483.
12 Kobal, T., Li, Y., Wang, X., and Zhu, A, junio 2022. “Digital Predistortion of RF Power Amplifiers with Phase-Gated Recurrent Neural Networks,” IEEE Transactions on Microwave Theory and Techniques 70 (6): 3291–3299.
13 Hu, X, et al., agosto 2022. “Convolutional Neural Network for Behavioral Modeling and Predistortion of Wideband Power Amplifiers.” IEEE Transactions on Neural Networks and Learning Systems 33 (8): 3923–3937.
14 Brihuega, A., Anttila, L, and Valkama, M. agosto 2020. “Neural-Network-Based Digital Predistortion for Active Antenna Arrays Under Load Modulation.” IEEE Microwave and Wireless Components Letters 30 (8): 843–846